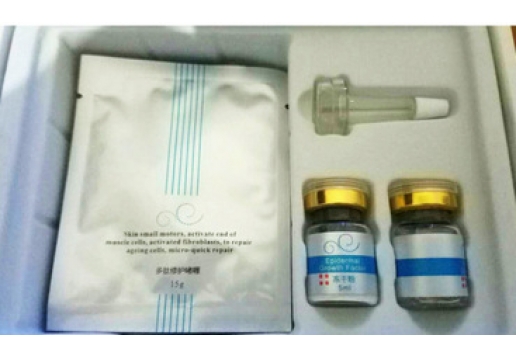
>
按分类查找
按功效查找
按其他查找
好肤希美白淡斑产品基本都有,因为太忙,有的没上架,或部分没更新,找不到请咨询在线客服
近期1012次展现(15次访问)
近期561次展现(14次访问)
近期925次展现(14次访问)
近期833次展现(18次访问)
近期1104次展现(21次访问)
近期806次展现(25次访问)
好肤希玉润美颜霜 30g
推荐商品
市场价:¥286元 优惠价:¥215元
近期12人展现 (0次访问)
市场价:¥396元 优惠价:¥297元
近期14人展现 (0次访问)
市场价:¥710元 优惠价:¥403元
近期10人展现 (0次访问)
市场价:¥297元 优惠价:¥223元
近期21人展现 (0次访问)
精品专卖,6年老店客服工作时间 8:30-22:00